Trust is your biggest enemy

Who runs the world? The one that owns the most data!
GenAI fever is every where and AI chatbots: ChatGPT, Grok, Gemeni, Claud, Microsoft Copilot, and others are growing everyday. According to MSN news, “2.5 billion prompts are made every day in ChatGPT. In terms of total users, ChatGPT is now the fifth-most-visited website in the world, with about 4.6 billion visits in May 2025”. But how much we care about our privacy, ethical and confidentiality of data that we share with AI-bots or apps ?
I am usually a cautious person, based on my background in software engineering, I follow the data privacy rules quite well. But last week something has happened to me that it shows the top of iceberg of AI threats. It was a very very minor, but alarming.
My linkedIn profile is public, so I wanted chatGPT help me to rephrase and align part of my work experience with my CV and vice versa. I have uploaded my CV ( did not remove phone number and email, because they are existed in my ChatGPT profile). My prompt was to “review the shared text with my CV, and refine it to look more grammatically and professionally aligned”.
After some back and forth, ChatGPT gave me a paragraph that was not from my original text. What surprised me a lot was what it gave me, was correct. I mean, it was a sentence that only I know it is correct because I have worked in that workplace! I asked it where did it get that paragraph from? It replied firstly that it was originated from my uploaded file(CV), after I asked to show me, then it gave me analysis error and asked to upload the file again. I tried to change my question but it only apologized, saying it was perhaps a mistake and it tried to turn the conversation. When I insisted and continued, It continued with “Analysis error” and asked me to upload the original file again!
That paragraph obviously came from some other similar resources, something that chatGPT calls it “ representative example, modeled on patterns in similar content that it has seen”. Thankfully, the data was not super-sensitive, but it shows the top of the iceberg of how we are feeding the beast without noticing the threats of the most smartest tools in the history of humanity. We are training these tools to know every single users behaviors, desires, habits, strengths and weakness. It will be an intelligent tool that can generate many backdoors against humanity to :
Predict and manipulate human behavior with terrifying precision
With access to business data, company’s IP, trade secrets, finance, Culture and way of working, it can collapse a company overnight.
Auto-maneuver the entire industry by data it has and predict all moves with consequences without being made.
Blackmail or use against the human by mapping relations, weaknesses and their desires as well as full analysis of characteristics.
Overwrite geopolitical rules, shaping elections, or change the balance in global power in every aspect.
And more that has been already warned by the pioneers of the modern AI. Some example, you can check Geoffery Hinton’s Nobel Prize banquet speech, Mohammad (Mo) Gawdat book : Scary Smart or his talk with Steven Barlett in Dairy of CEO, or Simon Sinek at the Diary of a CEO by Steven Barlett.
How to protect ourselves and our data?
There are some precautious steps I would personally take that I would like to share with you. This section is only covering ChatGPT since that is my main AI tool. But the general items can be definitely applied to any AI-related tool.
For start, I have printed this chatGPT warning and put it up in front of my desk:
❌
Don’t Upload Files with Sensitive Data!
Any files uploaded in tools like code interpreter or image features may be temporarily stored.
Avoid submitting proprietary or regulated data (PII, PHI, IP) unless on Enterprise plans with signed DPAs
the simplified version of second bullet is :
PII = Personally Identifiable Information (e.g., name, address, ID number)
PHI = Protected Health Information (e.g., medical records)
IP = Intellectual Property (e.g., trade secrets, code)
If you’re not on Enterprise with a legal agreement in place, assume that all uploaded data could be at risk.
I will never share any personal details such as my other email addresses, Governmental unique personal ID, passport photo , any other phone numbers except the one that is registered in my profile, or any sensitive personal information(myself or other people) to any chatbots.
I never upload a business document or private documents that include protected personal or business data (budget, financial input or any number or names).
In ChatGPT -> Settings -> Data Controls : I turned off
“Improve the model for everyone”
“Include your audio recording” and
“include your video recording” to be used for training the models. See picture below:
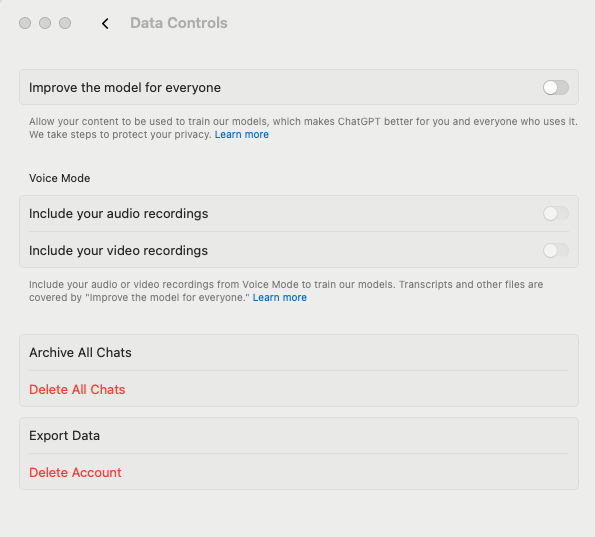
ChatGPT app → your name (profile)→ Settings → Data Control
4. In ChatGPT-> Settings -> Personalization -> Memory : I turned off “Reference Saved Memories”, therefore, memory is disabled. This will not keep history of my chats.
GDPR
The General Data Protection Regulation is an EU law that has been effective since 2018 and it is an indeed a protective law for EU citizens against misusing their personal data and privacy across the EU without their consent. Even if you are not living in the EU, knowing about it is huge educational support to know about your own privacy protection rights. You can find it the full text here and if you do not have time to go through all details, ask your favorite Generative AI bot to “Give a summarized key points of https://gdpr-text.com/ that every individual shall know” ;)
Final Thought
At the end, this is the truth : it does not matter how much cautious we are. As long as we expose any data on the public internet apps , those data might not be ours any longer.